Document Intelligence
An end-to-end AI pipeline that reads, extracts, classifies, and routes insurance documents automatically, cutting manual review time by 70% for a US insurance firm in its first month of operation.
The Project
A US insurance firm was processing thousands of documents every week by hand. Claims forms, policy documents, medical reports, and legal correspondence all went through a manual review queue that was slow, prone to errors, and expensive to maintain. The volume was growing faster than the team could scale.
We built a fully automated document intelligence pipeline that takes raw insurance documents in and returns structured, classified, actionable data out. The whole system went from brief to production in one month.
The Pipeline Architecture
From raw documents in to structured, classified, routed data out in a single automated flow
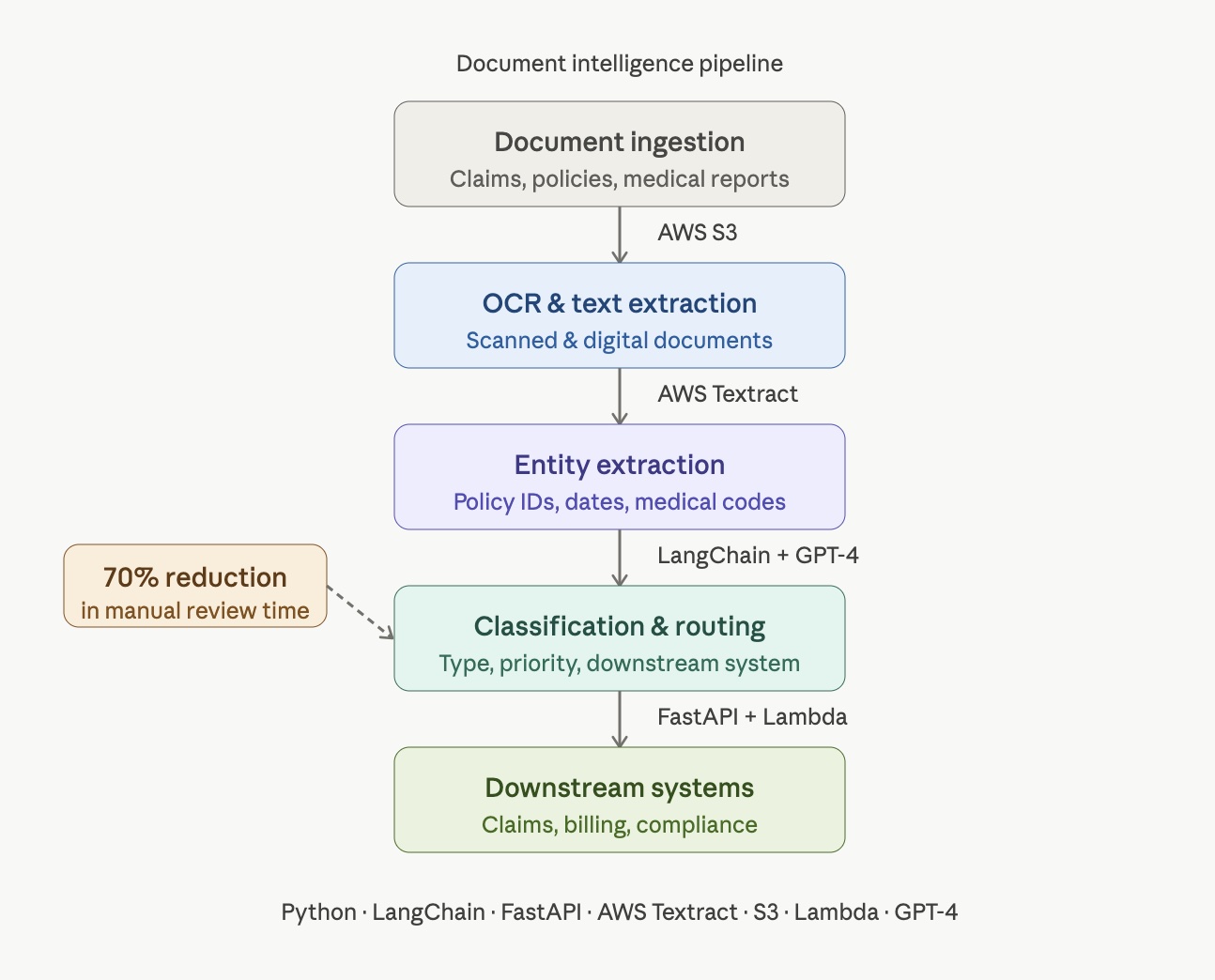
Manual document processing that could not keep pace with the business
A US-based insurance firm was drowning in paperwork. Claims forms, policy documents, medical reports, and legal correspondence were all being processed manually, which was slow, error-prone, and expensive. The team needed a smarter way to handle the sheer volume of incoming documents without scaling headcount, and they needed it to be accurate enough to trust in a regulated industry.
The documents themselves were the hard part. Insurance paperwork comes in every format imaginable, from scanned paper forms to dense legal PDFs, with critical information scattered unpredictably across pages. Entity extraction needed to be smart enough to find policy numbers, claimant details, dates, medical codes, and liability terms reliably across wildly inconsistent document structures.
The system also had to route documents correctly from day one. Getting a claim to the wrong team or missing a high-priority document during a peak period had direct financial and compliance consequences. Accuracy was not optional.
Accepts claims forms, policy documents, medical reports, and legal correspondence in scanned and digital formats, stored and queued via AWS S3.
AWS Textract handles accurate text extraction from both scanned paper documents and native digital PDFs, feeding clean text into the pipeline.
NLP models extract policy IDs, claimant details, dates, medical codes, and liability terms, tuned specifically for insurance document language.
Each document is automatically classified by type and priority, then routed to the correct downstream system without any manual intervention.
AWS Lambda handles processing at any volume, scaling automatically during high-claim periods without infrastructure changes or manual scaling.
LangChain ties the full pipeline together, managing document chaining, LLM calls, and context passing between stages in a single coherent flow.
An end-to-end pipeline from raw documents to structured routed data
We designed and delivered a complete document intelligence pipeline that takes raw insurance documents in and returns structured, classified, actionable data out. The pipeline starts with OCR via AWS Textract to extract text from scanned and digital documents, then passes the result into an NLP entity extraction layer fine-tuned on insurance-specific language.
The extraction layer pulls out policy numbers, claimant details, dates, medical codes, and liability terms reliably across inconsistent document formats. A classification stage then determines the document type and priority level. A LangChain-powered orchestration layer ties the whole flow together and routes processed documents to the right downstream systems automatically, whether that is claims processing, billing, or compliance.
The entire system runs serverlessly on AWS Lambda and was designed from the start to scale effortlessly during high-claim periods without any manual intervention.
Purpose-built for document intelligence at insurance scale
Python handled the core pipeline logic. LangChain provided LLM orchestration and document chaining across pipeline stages. FastAPI served as the REST API layer for integration with existing internal systems. AWS Textract handled OCR for both scanned and digital documents. AWS S3 managed document storage and queueing. AWS Lambda provided the serverless compute layer for automatic scaling. OpenAI GPT-4 powered entity extraction and document classification.
Seventy percent of manual review time gone in the first month
Manual review time dropped by 70% within the first month of the pipeline going live. The team stopped spending their days triaging routine documents and could finally focus on the genuinely complex edge cases that actually required human judgement. That shift alone changed how the team worked.
Error rates on data extraction fell significantly compared to what the manual process had delivered. The pipeline also handled its first high-claim period without any intervention, scaling automatically through AWS Lambda exactly as designed. The client described going live as one of the smoothest deployments they had experienced.
Processing documents at scale in a regulated industry?
We build document intelligence pipelines that handle volume, complexity, and compliance requirements. Tell us what you are working with.
Ideas, Guides, and
Industry Perspectives

AI Agents for Business: Real Use Cases and What It Costs to Build One in 2026
AI agents for business explained simply. See real use cases, how agents differ from chatbots, what you need to build…
Read Article
RAG vs Fine Tuning: How to Build a Custom AI Assistant on Your Own Data (2026)
RAG vs fine tuning explained in plain words. Learn how to build a custom AI assistant on your own business…
Read Article
How Much Does AI Development Cost in India? (2026 Guide)
A complete breakdown of AI development costs in India in 2026. Chatbots, ML models, LLM integration, and full AI products.…
Read ArticleLet's Build
Something Great
Tell us about your project and we'll get back to you within one business day with a clear plan and an honest estimate.